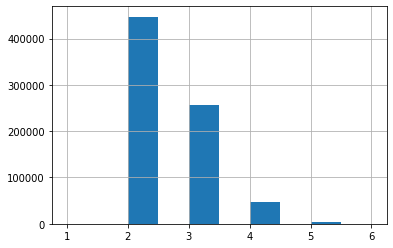
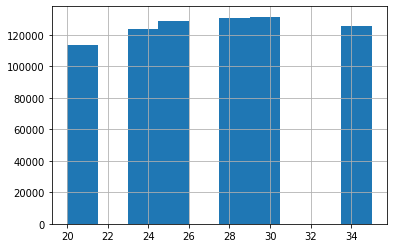
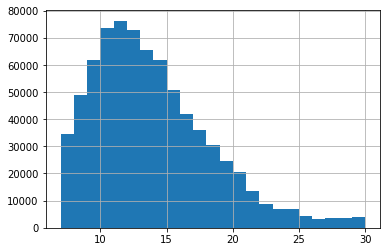
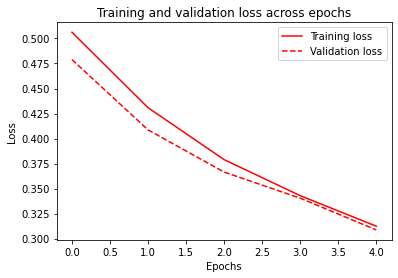
# Load ProteomeTools data from Figshare
!wget https://figshare.com/ndownloader/files/12506534
!mv 12506534 prosit_2018_holdout.hdf5--2022-09-27 22:45:17-- https://figshare.com/ndownloader/files/12506534
Resolving figshare.com (figshare.com)... 54.170.191.210, 54.194.117.36, 2a05:d018:1f4:d003:88c8:2c66:47e7:4f07, ...
Connecting to figshare.com (figshare.com)|54.170.191.210|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://s3-eu-west-1.amazonaws.com/pfigshare-u-files/12506534/holdout_hcd.hdf5?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIYCQYOYV5JSSROOA/20220927/eu-west-1/s3/aws4_request&X-Amz-Date=20220927T224517Z&X-Amz-Expires=10&X-Amz-SignedHeaders=host&X-Amz-Signature=3cae745acb61cdbeed831bae33ea71451bf3becf7404b7423a9fb848f55b3e3c [following]
--2022-09-27 22:45:18-- https://s3-eu-west-1.amazonaws.com/pfigshare-u-files/12506534/holdout_hcd.hdf5?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAIYCQYOYV5JSSROOA/20220927/eu-west-1/s3/aws4_request&X-Amz-Date=20220927T224517Z&X-Amz-Expires=10&X-Amz-SignedHeaders=host&X-Amz-Signature=3cae745acb61cdbeed831bae33ea71451bf3becf7404b7423a9fb848f55b3e3c
Resolving s3-eu-west-1.amazonaws.com (s3-eu-west-1.amazonaws.com)... 52.218.120.88
Connecting to s3-eu-west-1.amazonaws.com (s3-eu-west-1.amazonaws.com)|52.218.120.88|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 262781348 (251M) [application/octet-stream]
Saving to: ‘12506534’
12506534 100%[===================>] 250.61M 13.7MB/s in 20s
2022-09-27 22:45:39 (12.4 MB/s) - ‘12506534’ saved [262781348/262781348]